We are proud to announce that Scailable has been acquired by Network Optix.
For the announcement on the Network Optix website, move here.
From your CPU based local PoC to large scale accelerated deployment on NVIDIA Jetson Orin.
Edge AI solutions often start with a spark of imagination: how can we use AI to improve our business processes? Next, the envisioned solution moves into the Proof-of-Concept (PoC) stage: a first rudimentary AI pipeline is created, which includes capturing sensor data, generating inferences, post-processing, and visualization of the results.
Getting a PoC running is easy nowadays due to amazing code examples such as this one:
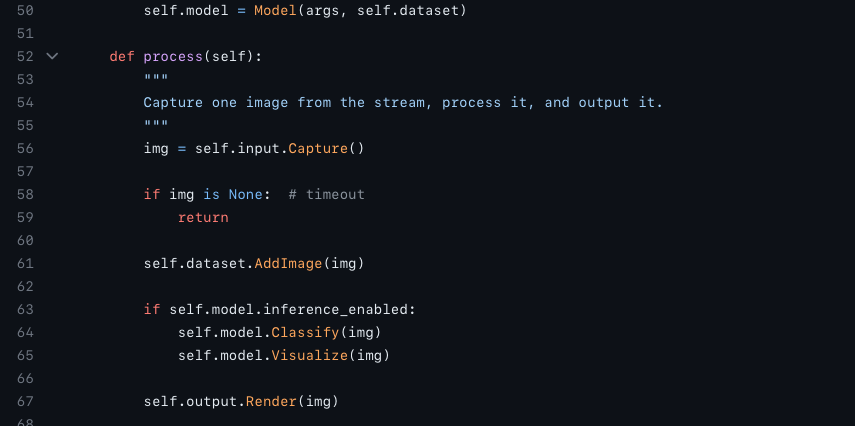
(Find the full source-code here)
However, deploying your PoC to an actual edge device — let alone to a whole fleet of edge devices — can be challenging. Your selected edge devices might have a different chip-set compared to your local development machine. You might want to ensure that you efficiently use the available hardware: specifically you want to use the GPU on the device for rapid video decoding and fast and efficient model inference.
In this post we will introduce how Scailable, an NVIDIA metropolis partner, ensures you can move rapidly from pipelines developed on your PC or in the cloud to remotely managed, highly performant, accelerated edge pipelines running on NVIDIA® Jetson™ Orin™devices. Scailable provides remotely manageable edge AI middleware that eliminates the complexity of hardware compatibility: think of it as “VMWare for edge AI”.
Furthermore, Scailable makes your pipeline development future proof, as Scailable’s middleware enables you to easily deploy your pipeline on newer generations of CPU and GPU’s, such as the NVIDIA Jetson Orin, as soon as those arrive. To that extent, the Scailable platform allows you to manage your pipelines across a heterogeneous fleet of edge devices, and manage your edge device hardware lifecycle independently from your AI model iterations.
We will start this post with a quick introduction of the most important edge AI deployment terms, and subsequently demonstrate how to take a vision pipeline into the Scailable platform to deploy it to a fleet of devices. At the end of this post we will discuss the benefits or using Scailable middleware when developing your own edge AI solution.
Not interested in the long read? Watch the video below for a quick intro:
1. Introducing managed edge AI middleware
Assuming a vision based edge AI solution — i.e., the input to the pipeline is a camera stream — we briefly cover all the terms relating to the Scailable middleware both on device, and in the cloud.
1.1. Modular edge AI pipelines
Let’s focus first on the middleware on the edge device. From the earlier code example, in python, the core of a vision based AI solution pipeline might look like this:
# python (pseudo-) code for image capture, model inference,
# and output rendering:
img = self.input.Capture() # Image capture / stream decode
if self.model.inference_enabled:
self.model.Classify(img) # AI model inference
self.model.Visualize(img) # Prepare visualization
self.output.Render(img) # Render
Scailable effectively installs a highly efficient pipeline on supported edge devices containing these exact same steps. We often visualize our middleware like this:
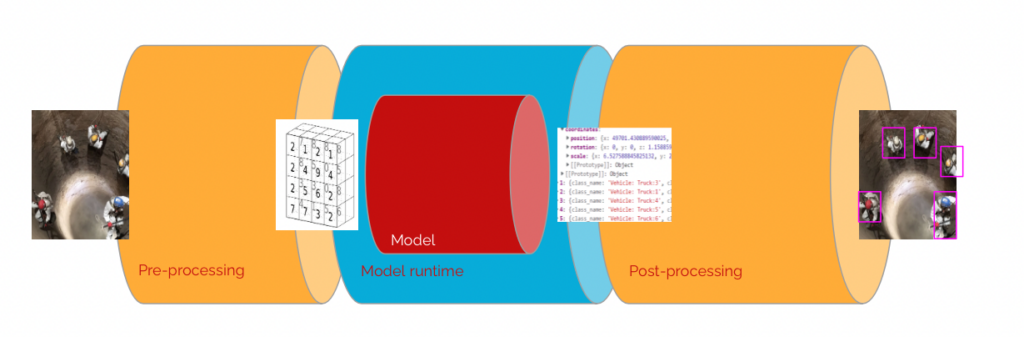
With Scailable middleware each part of the pipeline is fully modular and remotely configurable. We separate the following parts:
- Pre-processing: This first block of the pipeline ensure highly efficient sensor data collection and the appropriate data transformation(s) to provide an AI/ML model with the necessary input tensors. The vision pre-processing block will allow you to configure a camera (VFL, RTSP, MJPEG, etc. etc.) and configure image recoloring and resizing. The result is a tensor that is passed to the model runtime. Note that if possible, already in this step, the Scailable middleware will use the available GPU acceleration to (e.g.,) decode the incoming RTSP stream. Using the Scailable SDK one can easily add new pre-processing blocks to enable specific sensors. This block in the Scailable pipeline replaces the
self.input.Capture()call (and underlying code) in a way that is optimized for the target device. - The model runtime: The model runtime is the core work-horse of the middleware. The model-runtime ensures that the AI/ML model (for example a YOLO architecture DNN, or really any other type of model expressible in ONNX) is ran as efficiently as possible on the target hardware. Depending on the target hardware the model runtime will be vastly different, but to the developer this does not matter: the developer simply assigns one (or multiple) models to the pipeline on the device, and the middleware will ensure optimal deployment. This block in the Scailable pipeline replaces the
self.model.Classify(img)call (and underlying code) in a way that is optimized for the target device. - Post-processing: This block allows for flexible post processing. This might be the rendering of bounding boxes, blurring the content of bounding boxes, or more advanced — but common — features such as line crossing, masking, etc. Everything is remotely configurable and easily extended to fit your own needs. This block in the Scailable pipeline replaces the
self.model.Visualize(img)call (and underlying code) in a way that is optimized for the target device.
1.2. Cloud based Pipeline and model management
Once the Scailable middleware is installed on a target device it is manageable from the Scailable cloud platform. The Scailable platform effectively allows you to do three things:
- Upload and manage your models. You can import virtually any trained model in ONNX (or other standard formats such as TFLite) to the Scailable platform. Once uploaded, you can manage model versions and assign models to devices that have the Scailable middleware installed.
- Configure your remote pipelines. Next to assigning models, you can manage the full configuration of the pipeline remotely. This means that all pre- and post-processing steps can be configured from the cloud.
- Manage your fleet of edge devices. You might not manage just a single edge device, but a whole fleet of devices. You can flexibly group devices, manage pipeline configurations, and bulk assign and update models.
2. Getting started
While the above sets the stage for edge AI middleware, in this section we describe how to go about hands on. We will start with simple installation of the Scailable AI middleware on your selected edge device, move on to a simple “hello world” pipeline configuration example, and next demonstrate how to advance the pipeline for your own needs.
2.1. The one line install
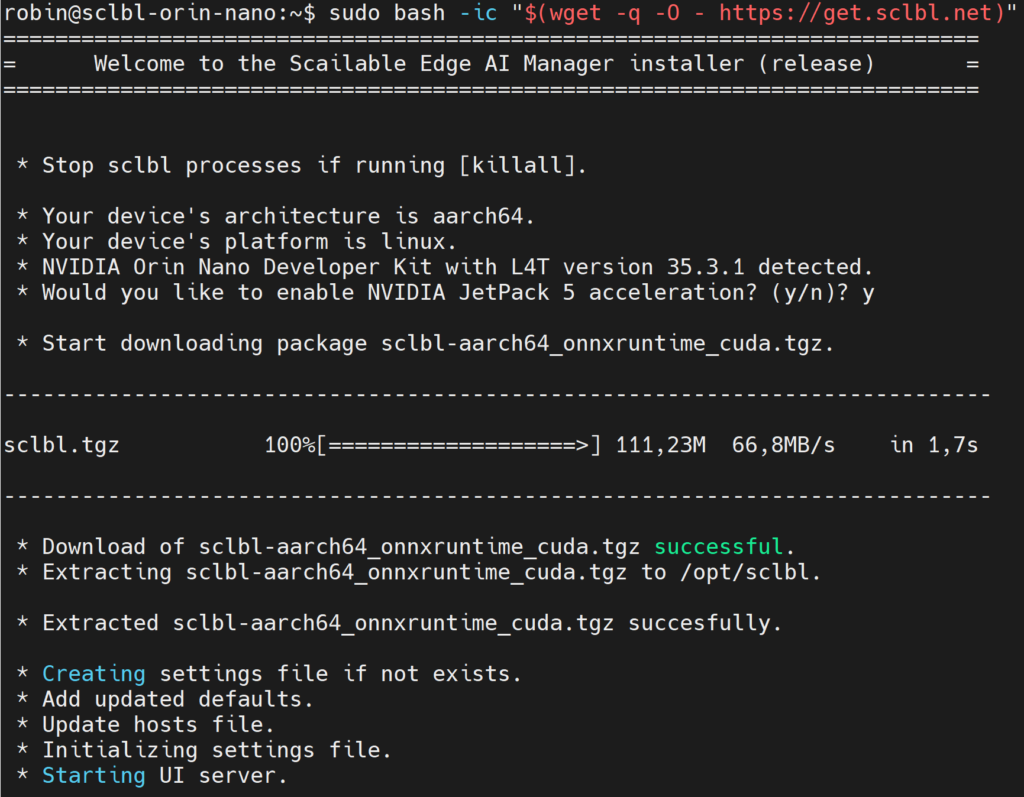
The easiest way to get started is to get your hands on a supported edge device running Linux. Next, in the shell, use the Scailable one-line install:
sudo bash -ic "$(wget -q -O - https://get.sclbl.net)"
Running the installation script will ensure that the appropriate version of the Scailable middleware, optimized for your hardware, is downloaded, installed, and started. Here is a small example of installation on a Jetson Orin device:
Note: The installation script can also be executed using an API key to immediately, upon installation, associate the device with your Scailable platform account using:
sudo bash -ic "$(wget -q -O - https://get.sclbl.net)" autoregister --key <key
2.2. “Hello world” pipeline configuration
After installation of the Scailable middleware you can — on device — navigate to the local configuration of your pipeline (note that all the settings are also remotely available and configurable from the Scailable platform). Logging in for the first time you will be asked to register your installation to the Scailable platform, allowing you to manage the device from the cloud.
After navigating to the local AI manager on the device — which is simply a front-end to configure your pipeline — you can now setup the input source, pre-processing steps, the model, post-processing steps, and determine what to do with the output.
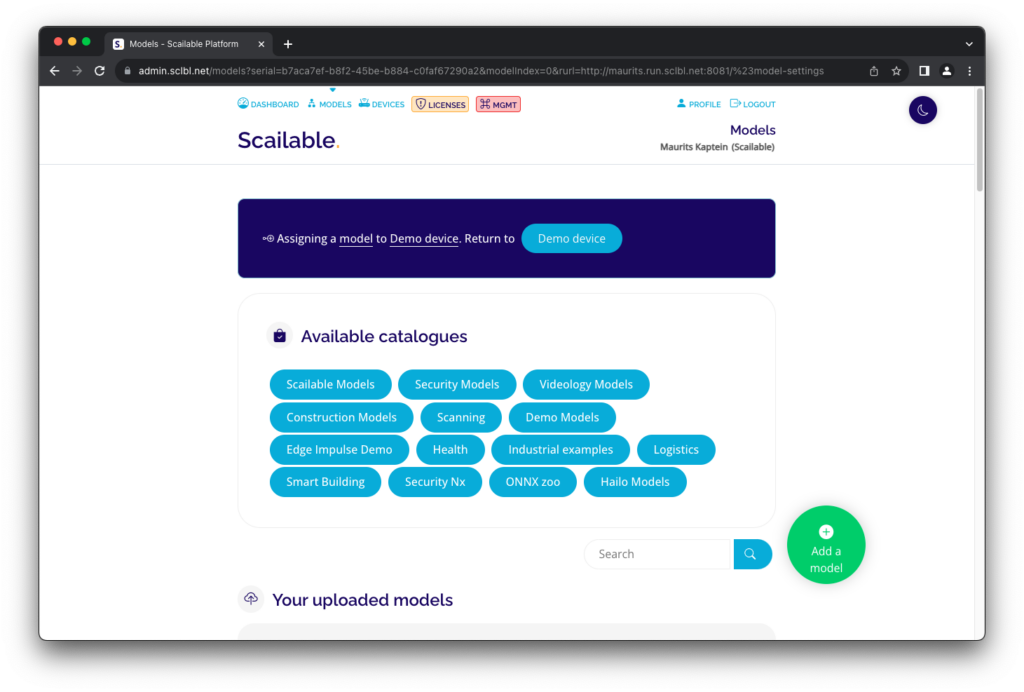
Model selection on the device looks like this,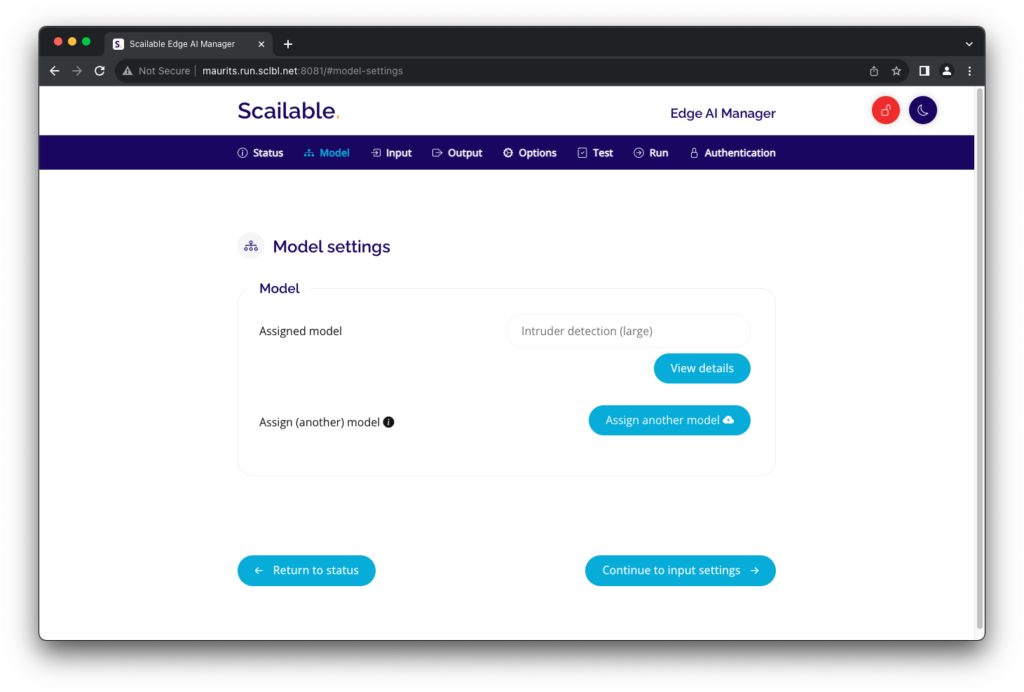 where clicking the “Assign another model” button will take you to the Scailable platform. Here you can either assign one of the Scailable off-the-shelf library models:
where clicking the “Assign another model” button will take you to the Scailable platform. Here you can either assign one of the Scailable off-the-shelf library models:
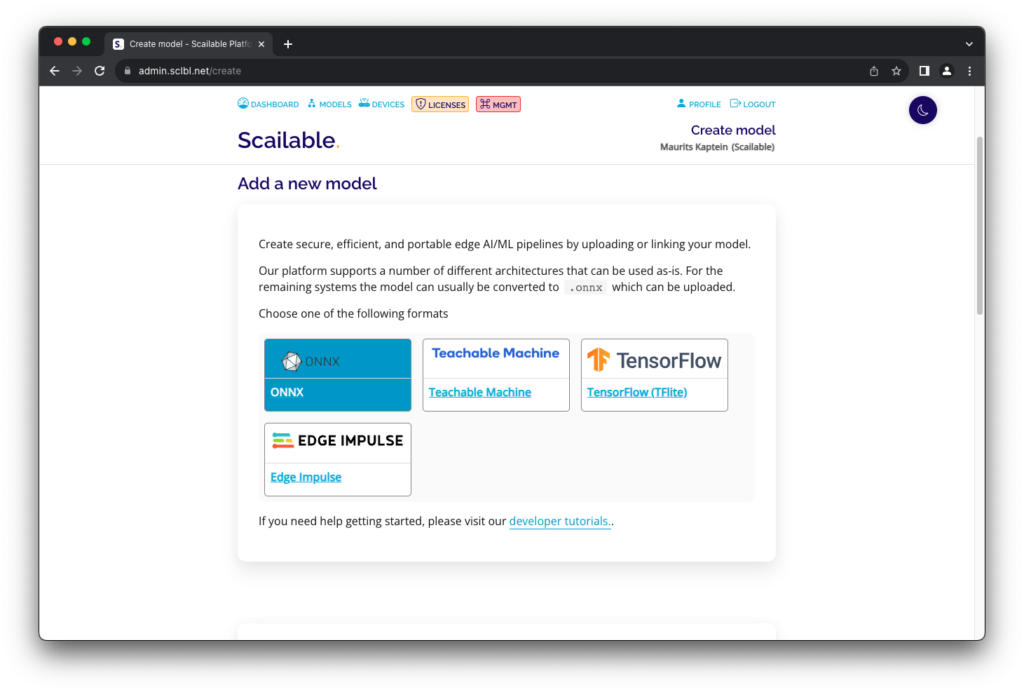
 or upload your own trained model from a variety of sources:
or upload your own trained model from a variety of sources:
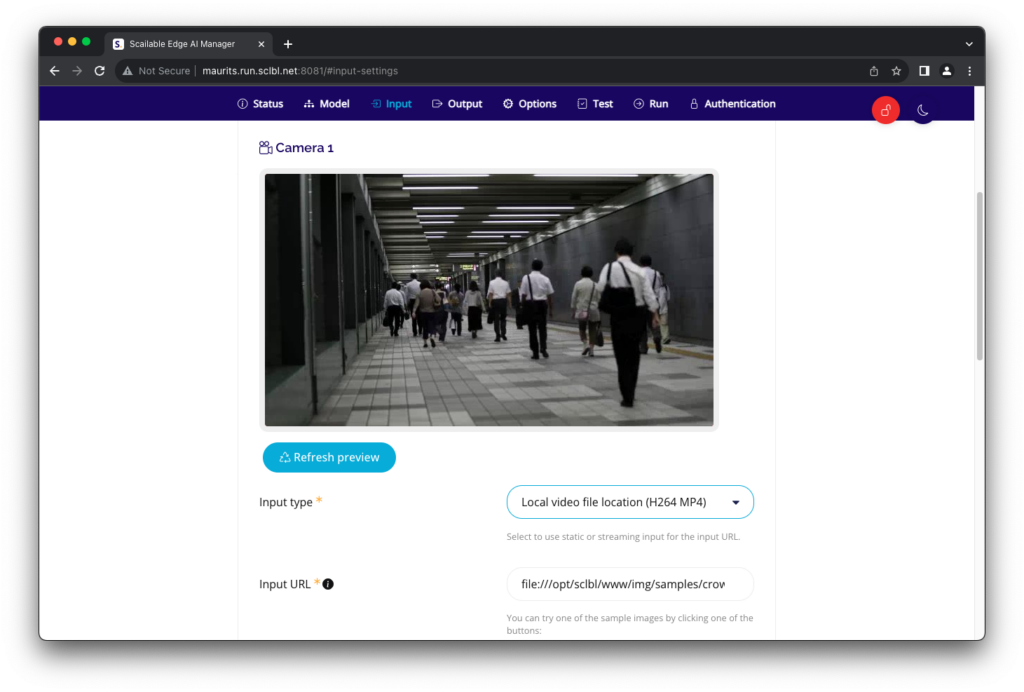
 For this quick “hello world” we select an “Intruder detection” model from the Scailable Security catalogue. Next, we configure the input stream and choose one of the available RTSP streams as an example:
For this quick “hello world” we select an “Intruder detection” model from the Scailable Security catalogue. Next, we configure the input stream and choose one of the available RTSP streams as an example:
 Subsequently, we can configure the post-processing steps,
Subsequently, we can configure the post-processing steps,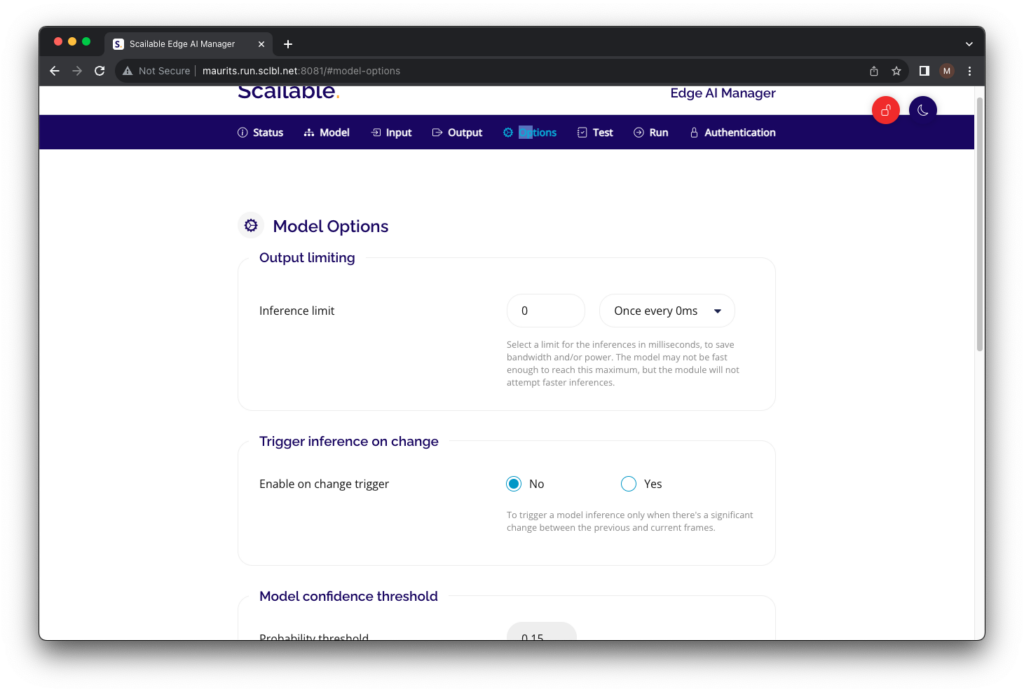 , set the model to run,
, set the model to run,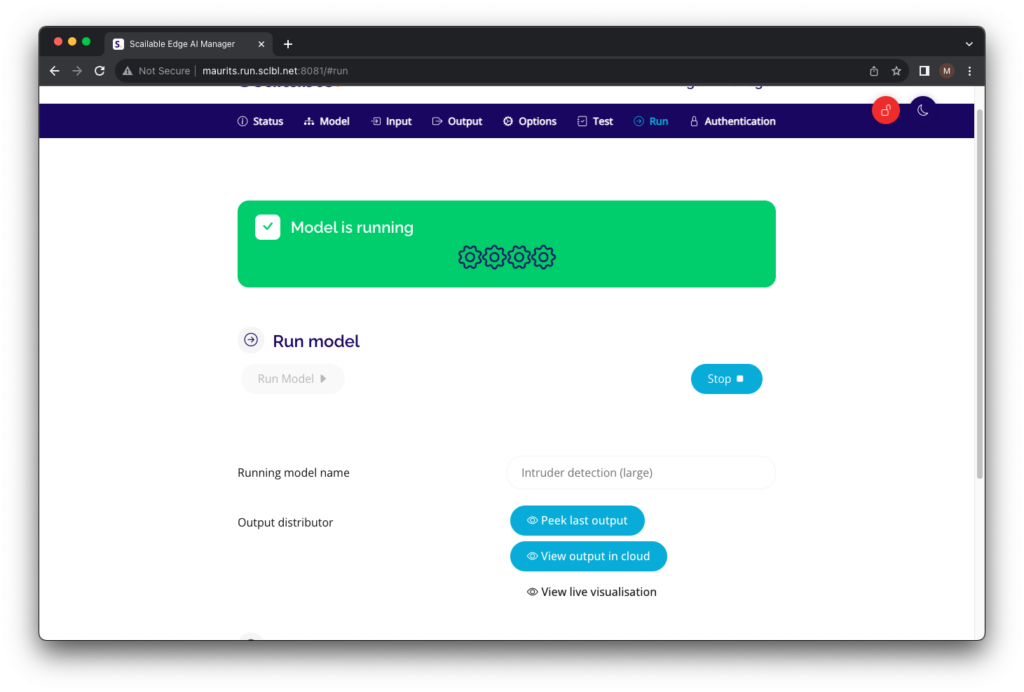 and view a preliminary visualization on the device:
and view a preliminary visualization on the device:
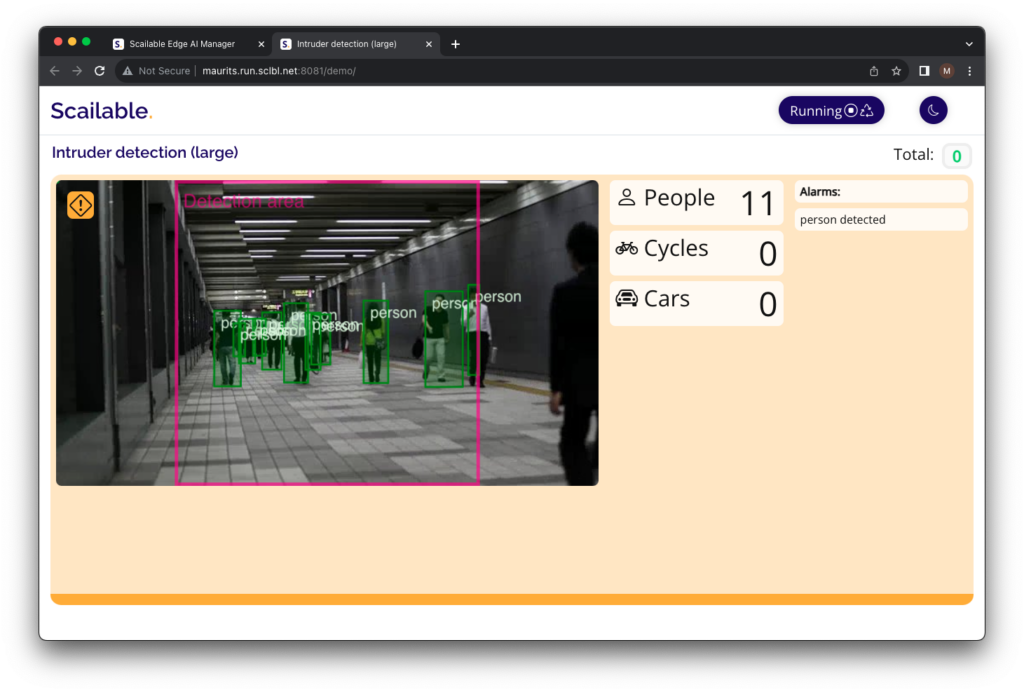
That’s it, you have created and deployed your fist Edge AI vision pipeline using Scailable middleware.
Note: A large number of pre- and post-processing options is available; please see the extended Scailable documentation to learn more: https://docs.scailable.net.
Note: Obviously, local visualisations are often not what you would like in a mature edge AI solution: The Scailable pipeline provides off-the-shelf integrations with higher level application platforms ranging from simple REST based results sharing to any application server of choice to plug-and-play integrations with (e.g.,) Network Optix and NodeRed.
2.3. Creating your own vision pipeline
The hello-world above demonstrate the ease by which one can use Scailable middleware to deploy edge AI solutions to any supported device, which include earlier NVIDIA Jetson generations. It also provides a gist of how to move from your current DYI pipeline over to Scailable:
- The image capturing (
img = self.input.Capture()in the earlier Python example) is simply replaced by configuration of the pre-processing block of the Scailable pipeline. You can select a large number of camera protocols, control frame rate, recoloring, and resizing, and ensure the right tensor is passed on to the model. - The model inference step (
self.model.Classify(img)) is simply implemented by selecting the correct model from your model library in the Scailable platform. We will detail adding custom models below. - The post processing and visualisation steps (
self.model.Visualize(img)andself.output.Render(img)are also configurable. Obviously, the available post-processing block might not cover all the operations one would like to carry out; thus, the Scailable AI manager is easily extendible with custom (pre- and) post processing.
Uploading a trained model to the Scailable platform is easy. On the platform side, this can be done by simply uploading a trained model file in one of the supported formats, or linking to one of the popular model-training tools supported by Scailable. The figure below shows the platform model upload page:
After configuring the pipeline and uploading the model, the actual deployment is simply a click of a button: over the air the most optimal version of your model (conversion happens cloud side) is send to the edge device in such a way that the full pipeline utilizes the hardware optimally.
Deployment using Scailable does not only allow you to effortlessly move from (e.g.,) a CPU only implementation to a GPU accelerated implementation, it also allows for mass deployment and model management. Devices can be grouped flexibly and both models and pipeline configurations can be assigned to groups of devices simultaneously:
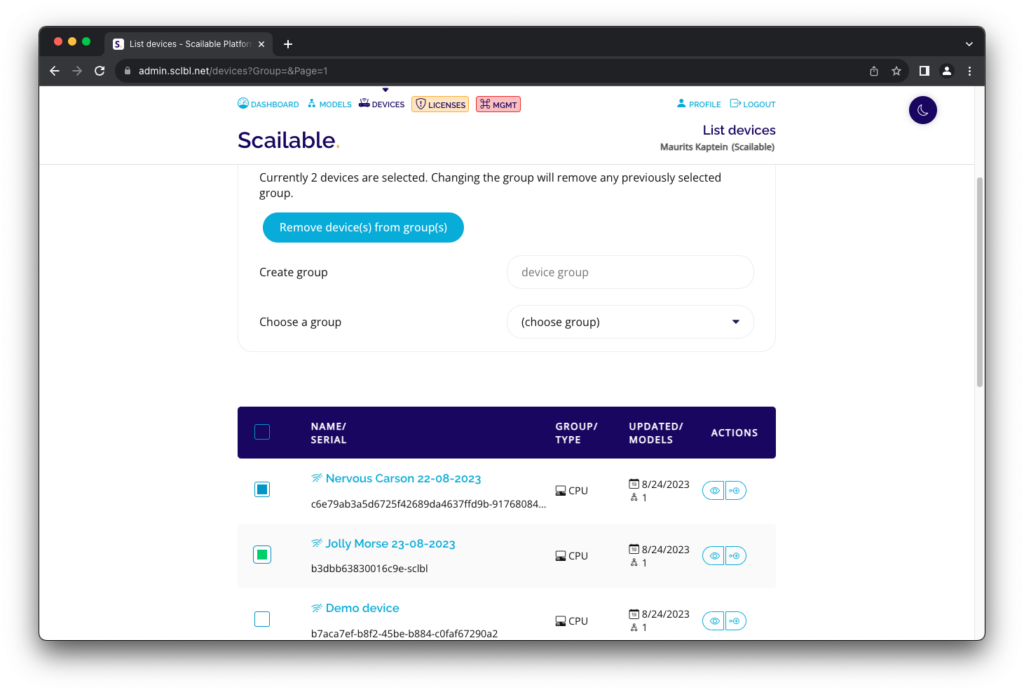
3. The benefits
Once you are all up and running, the benefits of the Scailable middleware are manifold. Let’s zoom in on a few…
3.1 … Accelerated time to market
So, with Scailable, your time to market is shortened significantly by sparing you the trouble of having to rebuild you whole pipeline for your target device. This makes you functionally independent from the hardware thus allowing for quick model development and improvement, without having to worry about the deployment target. From a hardware side this makes that we can select the hardware we need for the deployment context instead of the hardware that happens to align with our AI training tools.
However, it is not just the first model deployment that is faster. It is the speed up of iterations of your edge AI pipeline that truly brings value: Quickly iterate a model while training, and deploy it to a subset of (test) devices. If the model performs well, effortlessly roll it out to your whole fleet, without any re-engineering. The ability to iterate quickly ensures that your solution is ultimately successful.
3.2. …Cutting engineering costs
It is relatively easy to provide a “ballpark” figure of the time usually spend for deploying an edge AI pipeline. Here is a (highly) conservative estimate for the time that is consumed when creating and managing (with 2 model updates a year) a fleet of 100 (identical) edge AI devices:
- Let’s assume it takes roughly 24 hours (3 days) to sort out the image on a single device. Let’s further assume this image can be copied within 30 mins to each of the other devices. So that totals roughly
(24 + 100*1/2) = 74hours. - Let’s assume it take roughly 5 engineering weeks to code up the complete model pipeline on the target device. That’s roughly 180 hours. And let’s be very friendly here and say that this pipeline can be copied to the devices with the software update in point 1 above so scaling to all devices does not costs you extra.
- Let’s assume you took a model in a format that can simply be copied to the device. So, although often this process can actually take weeks, let’s be extremely gentle and count 0 hours. Finally, let’s assume that twice a year you update all of the devices with a new model. Let’s give it 2 hours of configuration per device per model update, thus calculating roughly
2*2*100 = 400hours.
Well, over the course of a year this effectively lower-bounds the engineering involved in creating and managing an edge AI solution across 100 devices at 74+180+400 = 654 hours. An experience engineer (one that might be able to actually do the tasks above in the hours projected) will at least set you back $100 dollars an hour. So, that’s (and again “lower-bounding-the-at-least” here) $65.400,-.
Now, with Scailable things are very different. You can buy edge devices with the Scailable AI manager pre-installed (yes, that saves you all of step 1 and step 2). You can simply configure your model using the Scailable platform, and, over-the-air, update the model to a group of devices in one go. This will take you about 30 mins tops. Ok ok, so that’s 1 hour for the bi-yearly model updates. However, that simply supports the final conclusion that you can use the Scailable platform, and the Scailable AI manager installed on each of the 100 devices, for a fraction of the original engineering cost.
3.3. …Heterogeneous installed base support
Over time, your installed base of edge devices will grow. As new version of hardware and accelerators arrive, you will want to leverage those new capabilities and savings in cost, power consumption etc. As such, you’ll end up managing 4-5 generations of hardware in the field, in combination with regular AI model updates. Because of this heterogeneous installed base, your cost of deploying and managing your AI pipeline across this fleet explodes beyond what was calculated in the previous paragraph. And the chance for errors increases.
With Scailable middleware, the hardware is abstracted from your AI pipeline. This allows you to evolve and enhance your pipeline asynchronously from the lifecycle management of your fleet of installed edge hardware. Using Scailable, your AI development team can work independently from your field ops team, largely improving the efficiency of your operations and enabling your data scientists to iterate much faster.
3.4. …Inference speed improvements
The Scailable pipeline is highly performant. Obviously, any middleware solution will add a small abstraction layer (which enables the OtA updates and modularity). That said, once deployed within a Scailable pipeline, you effortless move from one target to the other. Moving to Jetson Orin will buy you huge performance gains immediately.
3.5. …And improvements you had not yet thought of…
If this is truly your first edge AI development project, you probably did not think about collecting new data for future training, versioning models over devices, grouping devices, integrating with higher level application platforms, etc. These are all benefits you get from using Scailable middleware. For example, once a pipeline is deployed on an edge device, you can effectively configure a simple post-processing option to store input data (i.e., images) and send these to your cloud for future model training. This can be done randomly, or based on rules depending on model output. Hence, the Scailable middleware will allow you to close the model training loop, even when deployed in the field.
Wrap up
In this post we have tried to explain how to quickly move your local, PoC, AI pipeline to any Scailable supported edge device. As Scailable provides full Jetson Orin support, your move onto Jetson Orin is a great time to adopt Scailable middleware. Scailable will make the transition effortless and future proof.
In this blog-post we have not shown the extensive capabilities (and the opportunities for customization) of the Scailable middleware; if you are interested have a look at our docs.
In our upcoming posts we will analyze how moving from CPU to NVIDIA Jetson Orin, using Scailable middleware, increases the efficiency of your edge AI pipeline. For now, thanks for your interest!

Why We Are Joining Network Optix
Today, the entire Scailable team is joining Network Optix, Inc., a leading enterprise video platform solutions provider headquartered in Walnut Creek CA, with global offices in Burbank CA, Portland OR (both USA), Taipei Taiwan (APAC HQ), Belgrade Serbia, and shortly in Amsterdam (EU HQ). Network Optix, since its founding, has set out to “solve” video […]

Scailable supporting Seeed NVIDIA devices
We are excited to announce support for Seeed’s NVIDIA Jetson devices. The AI manager, and all our edge AI development tools, can now readily be used on Seeed devices. As we all know, edge AI solutions often start from creative ideas to optimize business processes with AI. These ideas evolve into Proof-of-Concept (PoC) phases, where […]
Allxon and Scailable Unite to further Revolutionize Edge AI Deployment
In a groundbreaking development that promises to reshape the landscape of edge AI deployment, Allxon and Scailable have joined forces to unveil the Scailable AI Manager, a cutting-edge edge AI deployment middleware now available as a plugin in the Allxon Plugin Station. This strategic collaboration brings together the expertise of Allxon in image-based over-the-air (OTA) […]